Kafka是是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:实时监控、日志收集,持久化存储、消息系统:高吞吐、用户行为分析和追踪
# 安装启动
- 下载安装 (opens new window)
- 官方文档 (opens new window),中文文档 (opens new window)
- 压缩包安装,添加
安装目录/bin进环境变量,根据配置文件启动zookeeper、kafka - 启动
zookeeper
nohup bin/zookeeper-server-start.sh config/zk.properties &
- 启动
kafka
nohup bin/kafka-server-start.sh config/kafka1.properties &
# Kafka核心概念
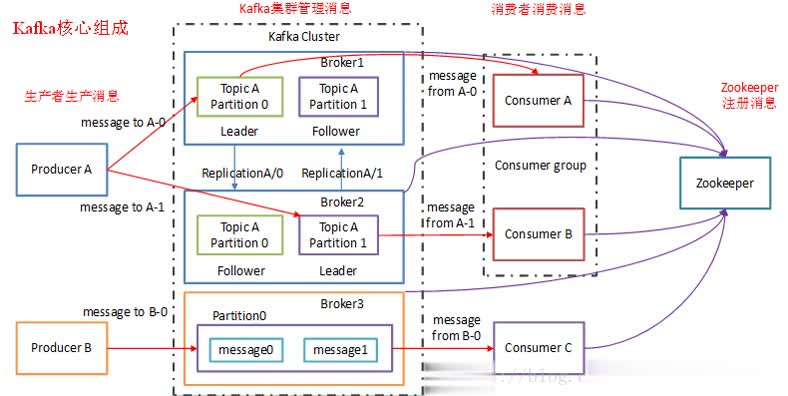
Topic(主题)
每一条发送到kafka集群的消息都可以有一个类别,这个类别叫做topic,不同的消息会进行分开存储,如果topic很大,可以分布到多个broker上;也可以理解为topic是一个队列,每一条消息都必须指定它的topic,可以说我们需要明确把消息放入哪一个队列
Producer(生产者)
向broker发送消息,通过zk定位到所有的broker(只需要向一个broker中生产数据,zk自动定位到其他brokder),方式有同步、异步,数据源可以有多种类型:flume、service、web app等
Consumer(消费者)
消费者:负责从broker拉取数据,消费模式有队列消费模式、发布-订阅消费模式
消费者组(Consumer Group):同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
Broker(代理)
一台kafka服务器就可以称之为broker.一个集群由多个broker组成,一个broker可以有多个topic
Partition(分区)
为了使得kafka吞吐量线性提高,物理上把topic分成一个或者多个分区,每一个分区是一个有序的队列。且每一个分区在物理上都对应着一个文件夹,该文件夹下存储这个分区所有消息和索引文件。
分区的个数设置:建议设置的比broker的个数多,保证所有的分区被broker均匀的分配,实现负载均衡
分区的表示: topic名字-分区的id
Replicas(副本)
建主题时可以指定副本因子,副本的个数,建议设置成 3,不建议设置的太大,容易造成数据的过分冗余
提供数据的高可用,安全性,提高容错,一个节点-----宕机了-----broker无法使用----partition无法被访问----message无法读写----无法提供数据服务,这样所有的Partition数据都不可被消费,所以需要对分区备份。其中一个宕机后其它Replica必须要能继续服务并且即不能造成数据重复也不能造成数据丢失。
offset(偏移量)
在每个partition分区下的消息都是顺序保存的,kakfa使用一个唯一的标识来记录它们在该分区下的位置,这个位置标识被称为offset,每条消息都追加到partition中,是顺序读写磁盘,因此效率很高
# 测试:
# 1. 创建一个topic的生产者和消费者
- 启动zookeeper
nohup bin/zookeeper-server-start.sh config/zk.properties &
- 启动kafka
nohup bin/kafka-server-start.sh config/kafka1.properties &
- 创建一个topic为
kafkatest
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkatest
- 创建一个名为
kafkatest的消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafkatest --from-beginning
- 创建一个名为
kafkatest的生产者(新开一个终端)
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkatest
模拟生产者产生数据:

模拟消费者处理数据:

# 2. flume+kafka+spark+inflxdb+grafana
启动zookeeper
启动kafka
启动flume
启动sparkt
提交spark作业
grafana配置inflxdb
监控面板从influxdb中获取数据实时显示